大数据时代下,数据科学成为兵家必争之地。如何在大数据分析的浪潮中找到更快、更高效的工具?聆听全球技术专家们分享如何使用科学的方法、流程、算法和系统来分析和提取数据中的见解,如何通过 NVIDIA 数据科学加速堆栈优化提升数据工作流性能。
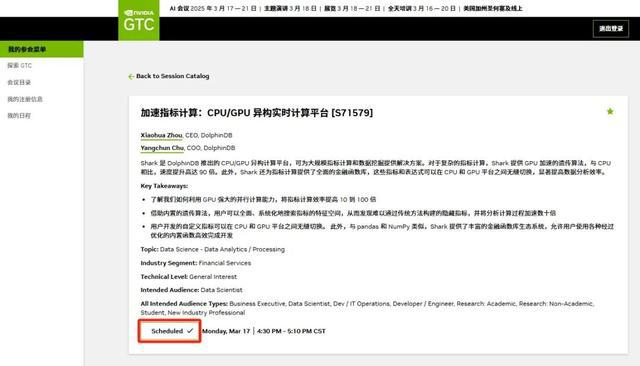
Shark 是 DolphinDB 推出的 CPU/GPU 异构计算平台,可为大规模指标计算和数据挖掘提供解决方案。对于复杂的指标计算,Shark 提供 GPU 加速的遗传算法,与 CPU 相比,速度提升高达 90 倍。此外,Shark 还为指标计算提供了全面的金融函数库,这些指标和表达式可以在 CPU 和 GPU 平台之间无缝切换,显著提高数据分析效率。
本场会议将提供详细的路线图,以便使用 NVIDIA 强大的 GPU 架构和软件工具训练专为资源稀缺语言(例如广东话/粤语)训练的大语言模型。了解如何使用 NeMo Curator 预处理数据集,以高效处理语言细微差别,并利用 NeMo Framework 优化模型训练和超参数调优。
通过本场会议,您将探索专为资源稀缺语言设计的架构调整,演示模型性能的量化,并走进重点介绍的实际应用案例研究。最后,您将拥有切实可行的实施和部署 LLM 的策略,以满足服务水平低下的语言社区的独特需求。
从信息检索到各种大数据工作负载(包括混合检索和留存分析),高效的集合操作可使许多应用受益。Bitmap 是构建高性能集合操作工具包的基本数据结构,其中一些工具包已经在行业中取得了巨大成功。与此同时,GPU 上基于位图的集合操作工具包仍需进一步优化。
本次演讲将分享基于位图的集合操作优化实践,详细阐述高效集合并集、交集、差集和其他操作的设计和实现要点,并展示如何与现有的基于排序数组的 GPU 集合操作工具包(如 Thrust)合作。通过充分利用 GPU 设备显存带宽和高效的线程调度机制,并通过位图减少显存占用,即可以在密集集合的运算上提供比现有工具包更高的吞吐量。
从网络搜索、广告推荐到 RAG,向量搜索已成为大规模应用的核心操作。然而不同场景对性能的需求差异显著,单一算法难以覆盖所有用例。相较基于 CPU 的解决方案,GPU 可加速索引构建与搜索吞吐量,实现数量级提升。
本场会议将由微软与 NVIDIA 共同展示微软在高性能向量搜索中的实际用例,探讨如何通过 NVIDIA GPU 与 cuVS 库加速复杂工作负载。从快速构建 DiskANN 索引到高吞吐量过滤搜索,涵盖算法、功能与优化策略,为 CPU 方案提供更高性价比的替代方案。
RAPIDS 开源库套件是加速 AI 与数据科学工作负载的基石,支持数据框架、机器学习、图分析、向量数据库及基于大语言模型的工作流。本场会议中,NVIDIA 技术专家将带领数据科学家与工程师了解新功能、零代码变更接口、强大的优化方案,并展望未来发展方向。
随着数据规模与复杂性激增,性能优天博体育平台怎么样化对数据工程师与科学家至关重要。Polars 作为基于 Rust 的高性能 DataFrame 库,以效率著称。本场会议将探讨如何通过整合 NVIDIA RAPIDS 实现 GPU 加速数据处理,在无需重构代码的前提下提升性能。内容涵盖 GPU 后端集成、CPU/GPU 数据传输优化,以及过滤、聚合与连接等关键操作加速。通过 CUDA 实现显著性能提升,助力用户以天博体育平台怎么样最小代码改动释放算力潜能。
本场会议将汇集行业顶尖的数据科学实践者,分享加速计算落地经验。与会者将了解到数据科学家如何通过零代码变更接口优化 AI/ML 流程中的加速库,以实现效率提升与成本降低。
Corey NoletNVIDIA 机器学习、数据挖掘与向量搜索首席工程师
Lucene 长期主导搜索领域,部分原因是它在众多软件工具中扮演着基础角色。但随着非结构化数据的持续增长,以及 LLM 和生成式 AI 的不断进步,在现代搜索系统中支持大规模向量嵌入变得越来越重要。新发布的 lucene-cuvs 库通过整合 NVIDIA cuVS 实现 GPU 加速,显著提升 Lucene 的向量搜索能力。本场会议将解析 cuVS 如何通过近似最近邻与聚类算法加速查询与索引,分享关键性能基准,并探讨其对 Lucene 生态系统的深远影响。
AI 正在重塑各行各业,金融服务领域亦不例外。Visa 长期以来一直引领创新,通过 AI 技术为全球用户提供安全、无缝的个性化支付体验。本场会议将探讨 Visa 如何利用生成式 AI 重新定义支付未来,分享其在安全与便捷性方面的突破性实践,并解析金融场景中 AI 应用的独特挑战与解决方案。
交易欺诈检测年花费高达 430 亿美元。AI 通过多模型协同分析客户行为异常与欺诈模式实现精准识别。本场会议将分享基于开源 ML 框架、NVIDIA AI 工具及 Triton 推理服务器的端到端优化工作流。根据欺诈检测数据基准测试,与 CPU 相比,适用于 Apache Spark 的 RAPIDS 加速器在 Amazon EMR 上可将数据处理速度提升 14 倍,成本降低至 1/8。
向量搜索是高性能 AI 应用的核心,需兼顾实时与批量推理场景的灵活处理。本场会议将展示如何通过开源向量数据库 Weaviate 与 GPU 驱动的 cuVS 库优化搜索性能,深入对比 CPU 优化的 HNSW 与 GPU 优化的 CAGRA 算法,并探讨混合 CPU/GPU 架构实施、索引转换与未来扩展策略。
加速数据科学工作流从未如此简单——通过预装 CUDA-X 库在 Google Colab 中一键启用 GPU 运行时,无需代码重构或库安装即可实现性能跃升。Gemini 提供多触点支持,帮助用户快速发现并生成加速代码。
Weights & Biases 联合创始人兼首席执行官 Lukas Biewald 将讲解企业在将生成式 AI 工作流从概念验证转向落地中的核心挑战与趋势,以及分享行业最佳实践,其中涵盖应用性能评估、成本优化与投资回报最大化策略。
复杂系统中的决策需求正突破传统方法的极限。本场会议将探讨 NVIDIA 在 GPU 加速决策优化中的突破性创新,包括原始-对偶线性规划(PDLP)与混合整数线性规划(MILP)启发式算法,展示这些先进技术在实际场景中提供的数量级加速与破纪录解决方案。
随着各行业在物流、调度及投资组合管理方面的需求日益增长,传统优化方法难以高效扩展。SimpleRose 集成了 NVIDIA cuOpt 技术,以加速线性编程(LP)与混合整数线性编程(MILP),在不影响高精度的同时实现了显著提速。通过本次会议,您将了解到:
点击链接查看 GTC 2025 注册教程,提前完成线上注册,便于后续预约和观看更多 GTC 精彩会议。

步骤二:下滑页面选择想看的会议,点击“Add to Schedule”绿色按钮


步骤四:完成登录后,重新扫码或打开链接进入会议目录。点击希望预约会议的“Add to Schedule”绿色按钮预约该会议,跳转到新页面后再次点击,状态变为“Scheduled”即预约成功。
GTC 2025 将于2025 年 3 月 17 至 21 日在美国加州圣何塞及线上同步举行,扫描下方海报二维码,立即注册线上大会或购买现场参会门票。
特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。
“凭什么让我滚出中国!”加入日籍的乒乓球天才张智和,回四川祭祖,遭乡亲强烈抵制
3-2,25岁广州队旧将发威,中甲第11掀翻中甲第10,陕西劲旅4连胜
伊姐端午热推:电视剧《紫川之光明王》;电视剧《错嫁世子妃》......
疯狂建设「有求必应屋」!!中国新闻史重点笔记重修好啦!!记得来看呀!!